为何需要数据科学?
举例:假设你是医生,判断病人症状不一定都很准确,尤其对于缺乏经验的医生来说,会发生误诊。人类的判断力有一定局限性,有限、主观的经验和不完备的知识都会影响判断力,从而导致无法获得更准确的结论。
数据科学依赖数据集,我们通过计算机和算法可以做到:
·从大型数据集中发现隐藏的趋势
·充分利用发现的趋势预测
·计算结果出现的概率并获得准确的结果
(本篇纯入门级别)
准备数据
数据格式
数据以表的形式表示
行:数据点,代表观测结果
列:变量,也叫属性、特征、维度
变量类型
①二值变量:01
②分类变量:男女
③整型变量:车辆数
④连续变量:小数表示,比如“支出”
变量选择
是一个试错的过程,需要根据反馈不断更换变量。
一个思路是用简单的图来研究变量间的相关性。
特征工程
有时需要做一些处理才能获得最佳变量。
除了对单个变量进行重新编码外,还可以合并多个变量,这叫降维。
缺失数据
①近似:
二值变量或分类变量可以用众数替代
整型变量或连续变量可以用中位数替代
②计算
③移除:除非万不得已,否则不这样做
选择算法
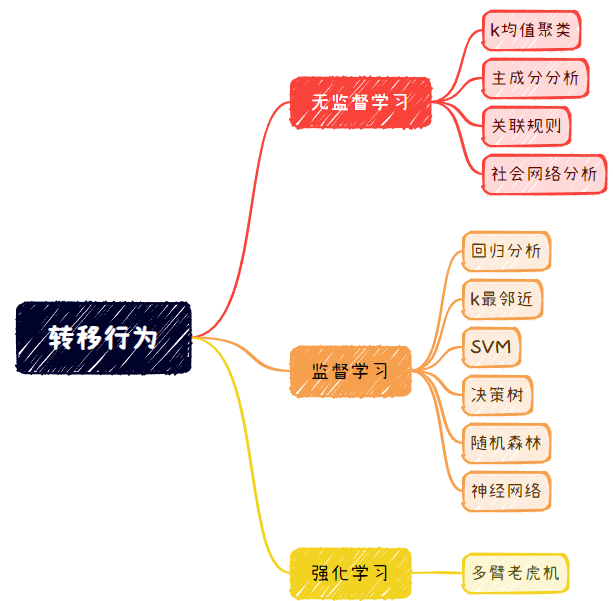
无监督学习
目标:找到数据中隐藏的模式
我们不知道要找的模式是什么,要依靠算法从数据集中发现模式
监督学习
目标:使用数据中的模式做预测
监督学习算法的预测都基于已有的模式
强化学习
自身可以通过反馈结果不断改进
是不是很像模电里面的反馈电路
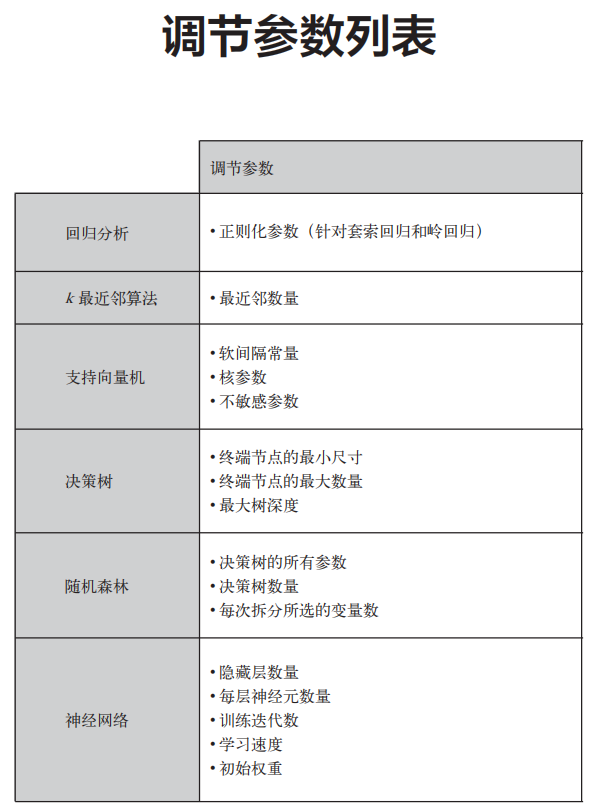
参数调优
评价模型
准确率
表述举例:对于XXX问题,我们的模型在90%的时间里都是对的
混淆矩阵
回归指标
由于回归预测使用连续值,因此误差一般被量化成预测值和实际值之差,惩罚随误差大小而不同。
典型:均方根误差
缺点:对异常值极其敏感
验证
评估模型对新数据的预测准确度,
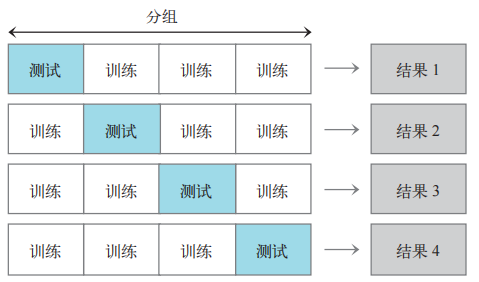
如果原始数据集很小,可以考虑交叉验证:把数据集分块,对模型反复测试,取结果平均值
如果交叉验证结果表明模型的预测准确度较低,可以重新调整模型的参数或者重新处理数据。