These are the nights that never die!
Introduction to K-Nearest Neighbors Classifier
KNN is a very easy algorithm.
kNN classifier is to classify unlabeled observations by assigning them to the class of the most similar labeled examples. Characteristics of observations are collected for both training and test dataset. For example, fruit, vegetable and grain can be distinguished by their crunchiness and sweetness.
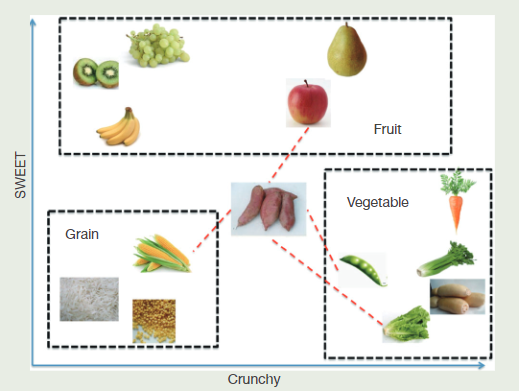
There are two important concepts in the above example.
1.Distance
Minkowski Distance
In fact, it`s not a sort of distance, but a defination of distance.
where p is a variable parameter
if p = 1
if p = 2
if p =
Euclidean distance
By default, the knn() function employs Euclidean distance which can be calculated with the following equation
where p and q are subjects to be compared with n characteristics.
2. Parameter K
The appropriate choice of k has significant impact on the diagnostic performance of kNN algorithm.
The key to choose an appropriate k value is to strike a balance between overfitting and underfitting.
Some authors suggest to set k equal to the square root of the number of observations in the training dataset.
Let’s talk about the differences between approximate error(近似误差) and estimation error(估计误差):
approximate error: a taining error for training set
只能体现对训练数据的拟合表现。
estimation error: a testing error for testing set
可体现对测试数据的拟合表现,也就是体现出泛化能力,因此对模型要求是估计误差越小越好。
In practical applications , we usually choose a pretty smaller parameter k which aims to get the best parameter k.
Implementation
1 | from sklearn.datasets import load_iris |
Evaluations
Advantages
①High accuracy(高精度)
②Insensitive to outliers(对异常值不敏感)
③No data entry assumes(无数据输入假定)
Disadvantages
High computational complexity and high spatial complexity (计算复杂度高、空间复杂度高)
Differences Between Regression and Classification
| Regression | Classification | |
|---|---|---|
| Output | Quantitative(定量) | Qualitative(定性) |
KNN Regression
Data normalization(数据归一化处理)
使用零均值归一化:
Code
1 | import numpy as np |
