SVM需要大量的数学理论基础,推导和原理很麻烦但是有趣,为了让大家看的更舒服一些,笔者干脆整了个活;理解SVM总共有三层境界,受笔者数学水平所限,只能理解两层,第三层境界是证明SVM,欢迎大佬们来🔨
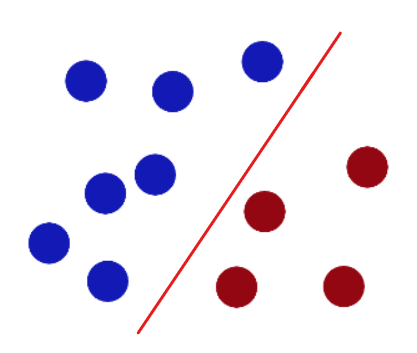
基础 先问是什么 蔡徐坤送给你很多🏀和🐔,现在你在操场上要进行分类,是这样分布的:
KUN说:聪明的你,一定知道怎样把它们分类对吧?我希望,你把🏀和🐔联系起来想一想,嗯?🤾♂️
哦!你画一条线就可以了!
不过KUN哥故意多放一只🐔,这只🐔开始打篮球了,这该怎么办腻?
于是你的CPU借助了图灵之力,又重新画了一条线,这样问题就解决了。不过KUN哥并不打算放过这个小黑子:“这样你会么?”
画直线不好使,那画一条曲线总可以吧,但是直接画不太妥,所以你直接一个铁山靠 ,将🏀和🐔从操场上靠飞了,然后你就像水果忍者一样,在空间中切出一个平面:
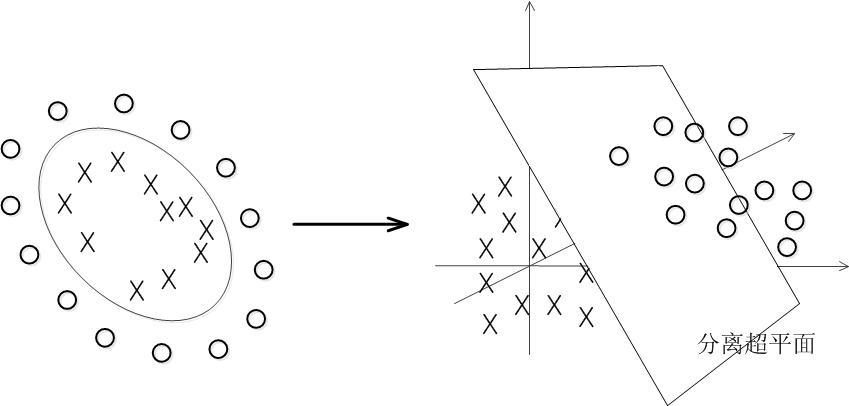
后来,这个故事在IKUN圈广泛流传,小黑子们把🏀和🐔统称为数据data ,线称classifier ,最大间隙叫optimization ,操场叫做hyperplane ,切法叫做Dimensionality reduction 。
好,你明白这是个啥了,那么具体理论要开始给你洗脑了。
梦开始的地方 👉《🍉📒》
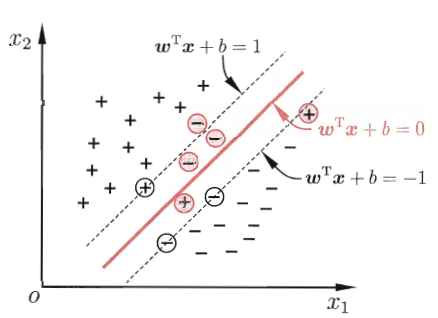
给定训练样本集
样本空间中,划分超平面按照如下线性方程来描述:
这个式子怎么理解呢?
ML中,向量默认为列向量,我们可以假设都是二维向量
🧐这不是初中数学嘛?
样本中任意点
这个展开就类似二维空间中的距离公式
假设超平面能将训练样本正确分类,即
距离超平面最近的这几个训练点使得最短距离就是分子取最小值为1,这样的点被称为“支持向量”(support vector),两个异类支持向量到超平面距离之和为
也被称为“间隔”(margin )
我们想做的是找到具有最大间隔的划分超平面,也就是
当然可以重写为
👋平方是去掉根号,为了方便计算
👆就是SVM基本型
继续深入 凸二次规划 看到这个概念可能很陌生,不过你已经学过高数了,你一定还记得凸函数 是什么
严格凸函数 没有等号,典型例子是
还有一个仿射函数: 最高次数为1 的多项式函数,形如
凸函数和仿射函数在一起就有了凸优化问题,如下定义:
且 为凸函数,且 为凸函数,且 为仿射函数,三者定义域内连续可微。
凸二次规划是凸优化的一个特殊形式,当目标函数
核心思想:在一定的约束条件下,目标最优,损失最小。
SVM就是典型的凸二次规划。
拉格朗日乘数法 大一学的针对等式优化,这里只针对不等式优化进行分析。
主要思想是将不等式约束条件转变为等式约束条件,引入松弛变量,将松弛变量也看作优化变量。
引入松弛变量
✍这里加平方主要为了不再引入新的约束条件,如果单单引入
由此我们得到Lagrange 函数
我们对
针对
①
约束条件
②
约束条件起作用且
综上,
所以方程组转化为
这就是大名鼎鼎的KKT条件
从原问题到对偶问题 🔍对偶问题是什么?与原问题等价的问题。
📂转化后的优点?
①对偶问题往往更容易求解;
②可以自然的引入核函数 ,进而推广到非线性分类问题。
👆推导KKT就是典型的转化对偶问题。
KKT 条件是强对偶性的充要条件 。
软间隔 在实际应用中,完全线性可分的样本是很少的,如果遇到了不能够完全线性可分的样本,我们应该怎么办?
所以我们提出一种解决方法:软间隔,允许个别🏀和🐔犯错误,也就是允许个别样本点出现在间隔带里面,为下一步核函数 做铺垫。
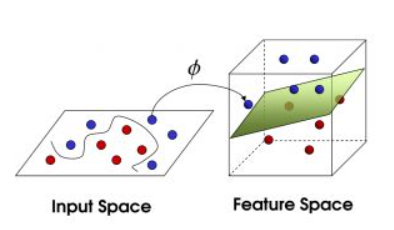
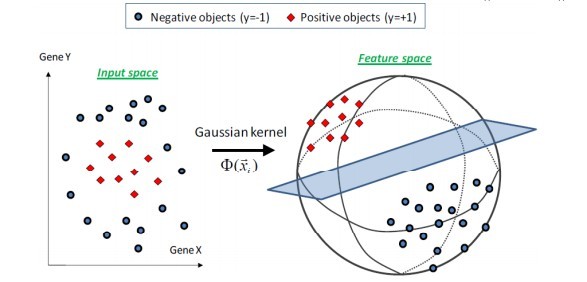
核函数Kernel 省流版:对数据降维打击。
对于线性不可分的情况,SVM选择一个核函数,把数据扔到高维 来解决原维度 的线性不可分问题。
支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射 到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。
下面我们讲讲核函数具体怎么做了什么的。
比如我们在二维直角坐标系中取3个点,作为标记
计算相似度公式我们这样写
if x near
if x far from
我在摸鱼的时候,你有在偷看概率论罢
对高斯分布一点也不陌生,我们把这种核函数叫高斯核,它的作用是升维计算。 高斯核的使用关键在
下面是常用核函数
然后我们回到预测函数,假设我们知道
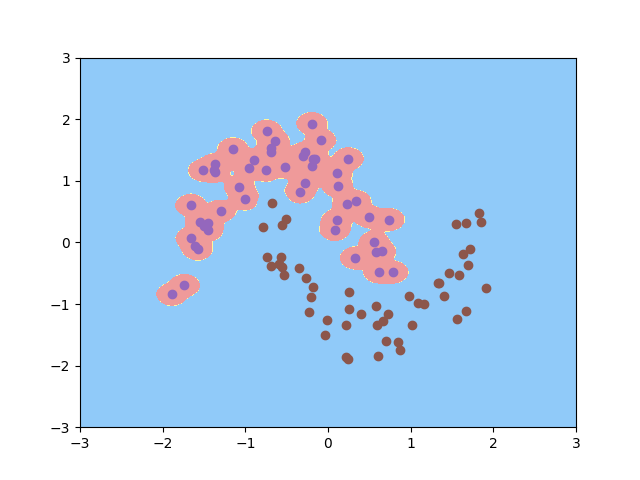
这样就得到了非线性的边界。
也就是说,SVM在处理非线性分类 中具有非常强大的优势。
处理噪声outliers 引入松弛变量(slack variable)
完整公式如下
同理,用上面的方法可以将限制或者约束条件加入到目标函数中,得到新的拉格朗日函数
我们让
将
Coding实现 分类模型举例 代码详解
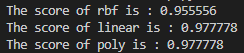
首先是3种SVM的准确性测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from dataclasses import dataclassfrom sklearn import svmfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split as tsiris = load_iris() x = iris.data y = iris.target x_train,x_test,y_train,y_test = ts(x,y,test_size=0.3 ) clf_rbf = svm.SVC(kernel='rbf' ) clf_rbf.fit(x_train,y_train) score_rbf = clf_rbf.score(x_test,y_test) print ("The score of rbf is : %f" %score_rbf)clf_linear = svm.SVC(kernel='linear' ) clf_linear.fit(x_train,y_train) score_linear = clf_linear.score(x_test,y_test) print ("The score of linear is : %f" %score_linear)clf_poly = svm.SVC(kernel='poly' ) clf_poly.fit(x_train,y_train) score_poly = clf_poly.score(x_test,y_test) print ("The score of poly is : %f" %score_poly)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from sklearn import svmfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split as tsfrom sklearn.preprocessing import StandardScalerfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.pipeline import Pipelinefrom sklearn import datasetsfrom sklearn.svm import SVCimport numpy as npimport matplotlib.pyplot as pltmoons = datasets.make_moons(noise=0.15 ) X = moons[0 ] y = moons[1 ] plt.scatter(X[y==0 ,0 ], X[y==0 , 1 ]) plt.scatter(X[y==1 ,0 ], X[y==1 , 1 ]) def SVC_ (kernel="rbf" , gamma=1 ): return Pipeline([ ("std_scaler" , StandardScaler()), ("linearSVC" , SVC(kernel="rbf" , gamma=gamma)) ]) svc = SVC_(kernel="rbf" , gamma=0.7 ) svc.fit(X, y) def plot_decision_boundary (model, axis ): x0, x1 = np.meshgrid( np.linspace(axis[0 ], axis[1 ], int ((axis[1 ]-axis[0 ])*100 )).reshape(-1 , 1 ), np.linspace(axis[2 ], axis[3 ], int ((axis[3 ]-axis[2 ])*100 )).reshape(-1 , 1 ), ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap custom_cmap = ListedColormap(['#EF9A9A' ,'#FFF59D' ,'#90CAF9' ]) plt.contourf(x0, x1, zz, cmap=custom_cmap) plot_decision_boundary(svc, [-3 ,3 ,-3 ,3 ]) plt.scatter(X[y==0 ,0 ], X[y==0 ,1 ]) plt.scatter(X[y==1 ,0 ], X[y==1 ,1 ]) svc = SVC_(kernel="rbf" , gamma=100 ) svc.fit(X, y) plot_decision_boundary(svc, [-3 ,3 ,-3 ,3 ]) plt.scatter(X[y==0 ,0 ], X[y==0 ,1 ]) plt.scatter(X[y==1 ,0 ], X[y==1 ,1 ]) plt.show()
回归模型举例 SVM回归代码详解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.svm import SVRlinear_svr = SVR(kernel="linear" ) poly_svr = SVR(kernel="poly" , degree=4 ) rbf_svr = SVR(kernel="rbf" ) x = np.linspace(0 , 3 , 50 ) y = x * x + 10 + np.random.uniform(0 ,2 ,50 ) x = x.reshape(-1 ,1 ) plt.scatter(x,y) linear_svr.fit(x,y) poly_svr.fit(x,y) rbf_svr.fit(x,y) print (linear_svr.coef_, linear_svr.intercept_) x_test = np.linspace(0 ,3 ,100 ).reshape(-1 ,1 ) plt.scatter(x,y, color="green" ) plt.plot(x_test, linear_svr.predict(x_test), color="red" , label="linear" ) plt.plot(x_test, poly_svr.predict(x_test), color="blue" , label="poly" ) plt.plot(x_test, rbf_svr.predict(x_test), color="black" , label="rbf" ) plt.legend() plt.show()
评价 Advantages:
①有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
②采用核技巧之后,可以处理非线性分类/回归任务;
③能找出对任务至关重要的关键样本(即:支持向量);
④最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
Disadvantages:
①训练时间长。
②当采用核技巧时,如果需要存储核矩阵,则空间复杂度为
③多分类存在困难,一般通过多个二类支持向量机组合来解决;
④模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。因此目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务。
后记 代码那里详解直接看链接网站