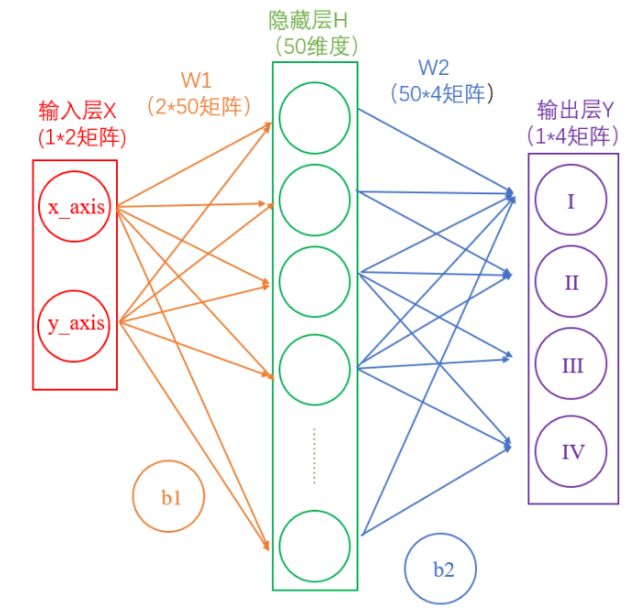
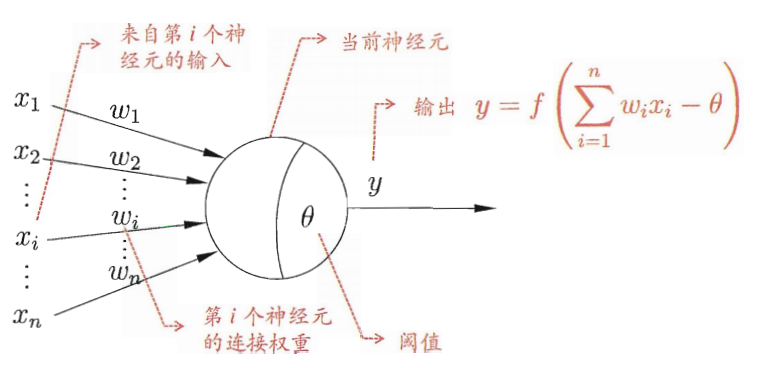
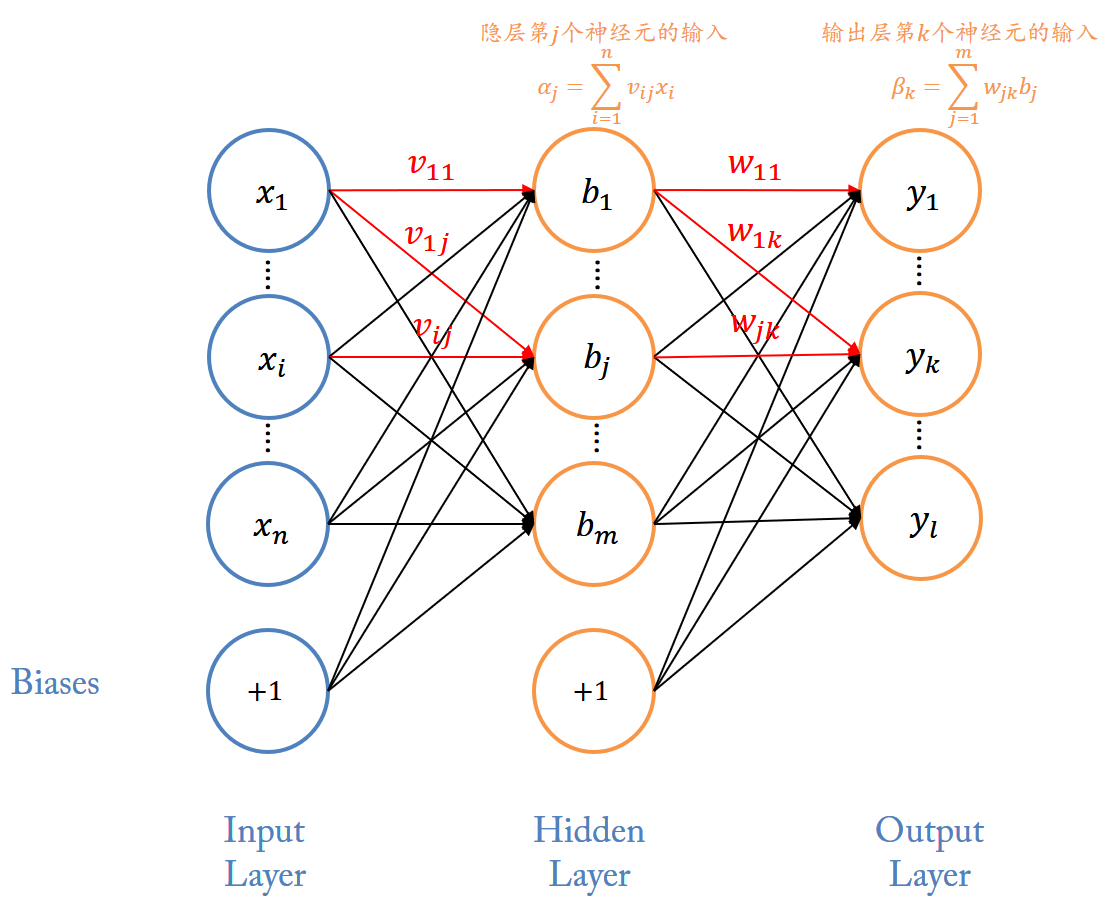
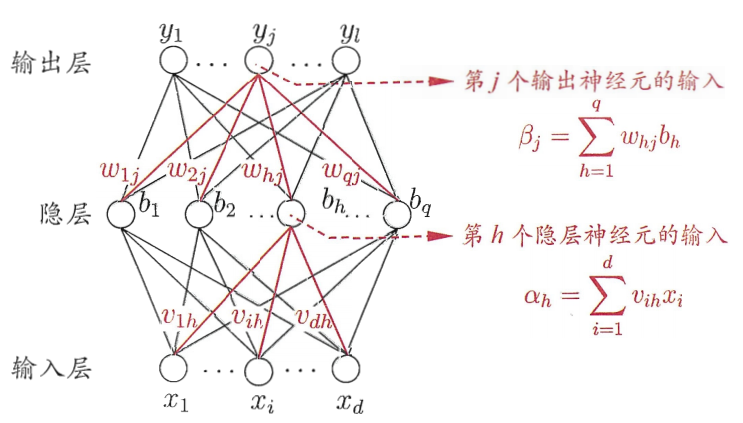
# 初始化偏差,除输入层外, 其它每层每个节点都生成一个 biase 值(0-1) self.biases = [np.random.randn(n, 1) for n in sizes[1:]] # 随机生成每条神经元连接的 weight 值(0-1) self.weights = [np.random.randn(r, c) for c, r inzip(sizes[:-1], sizes[1:])] deffeed_forward(self, a): ''' 前向传输计算输出神经元的值 ''' for i, b, w inzip(range(len(self.biases)), self.biases, self.weights): # 输出神经元不需要经过激励函数 if i == len(self.biases) - 1: a = np.dot(w, a) + b break a = sigmoid(np.dot(w, a) + b) return a defMSGD(self, training_data, epochs, mini_batch_size, eta, error = 0.01): ''' 小批量随机梯度下降法 ''' n = len(training_data) for j inrange(epochs): # 随机打乱训练集顺序 random.shuffle(training_data) # 根据小样本大小划分子训练集集合 mini_batchs = [training_data[k:k+mini_batch_size] for k inrange(0, n, mini_batch_size)] # 利用每一个小样本训练集更新 w 和 b for mini_batch in mini_batchs: self.updata_WB_by_mini_batch(mini_batch, eta) #迭代一次后结果 err_epoch = self.evaluate(training_data) print("Epoch {0} Error {1}".format(j, err_epoch)) if err_epoch < error: break; # if test_data: # print("Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)) # else: # print("Epoch {0}".format(j)) return err_epoch defupdata_WB_by_mini_batch(self, mini_batch, eta): ''' 利用小样本训练集更新 w 和 b mini_batch: 小样本训练集 eta: 学习率 ''' # 创建存储迭代小样本得到的 b 和 w 偏导数空矩阵,大小与 biases 和 weights 一致,初始值为 0 batch_par_b = [np.zeros(b.shape) for b in self.biases] batch_par_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch: # 根据小样本中每个样本的输入 x, 输出 y, 计算 w 和 b 的偏导 delta_b, delta_w = self.back_propagation(x, y) # 累加偏导 delta_b, delta_w batch_par_b = [bb + dbb for bb, dbb inzip(batch_par_b, delta_b)] batch_par_w = [bw + dbw for bw, dbw inzip(batch_par_w, delta_w)] # 根据累加的偏导值 delta_b, delta_w 更新 b, w # 由于用了小样本,因此 eta 需除以小样本长度 self.weights = [w - (eta / len(mini_batch)) * dw for w, dw inzip(self.weights, batch_par_w)] self.biases = [b - (eta / len(mini_batch)) * db for b, db inzip(self.biases, batch_par_b)]
defback_propagation(self, x, y): ''' 利用误差后向传播算法对每个样本求解其 w 和 b 的更新量 x: 输入神经元,行向量 y: 输出神经元,行向量 ''' delta_b = [np.zeros(b.shape) for b in self.biases] delta_w = [np.zeros(w.shape) for w in self.weights]
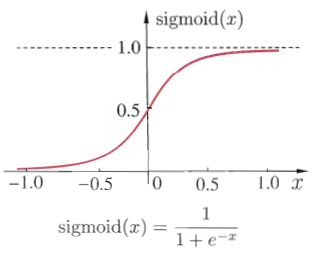
# 前向传播,求得输出神经元的值 a = x # 神经元输出值 # 存储每个神经元输出 activations = [x] # 存储经过 sigmoid 函数计算的神经元的输入值,输入神经元除外 zs = [] for b, w inzip(self.biases, self.weights): z = np.dot(w, a) + b zs.append(z) a = sigmoid(z) # 输出神经元 activations.append(a) #------------- activations[-1] = zs[-1] # 更改神经元输出结果 #------------- # 求解输出层δ # 与分类问题不同,Delta计算不需要乘以神经元输入的倒数 #delta = self.cost_function(activations[-1], y) * sigmoid_prime(zs[-1]) delta = self.cost_function(activations[-1], y) #更改后 #------------- delta_b[-1] = delta delta_w[-1] = np.dot(delta, activations[-2].T) for lev inrange(2, self.num_layers): # 从倒数第1层开始更新,因此需要采用-lev # 利用 lev + 1 层的 δ 计算 l 层的 δ z = zs[-lev] zp = sigmoid_prime(z) delta = np.dot(self.weights[-lev+1].T, delta) * zp delta_b[-lev] = delta delta_w[-lev] = np.dot(delta, activations[-lev-1].T) return (delta_b, delta_w) defevaluate(self, train_data): test_result = [[self.feed_forward(x), y] for x, y in train_data] return np.sum([0.5 * (x - y) ** 2for (x, y) in test_result]) defpredict(self, test_input): test_result = [self.feed_forward(x) for x in test_input] return test_result